
The Hidden Danger of Fine-Tuning Embedding Models in RAG Pipelines
Enterprise development teams are increasingly turning to fine-tuning as a quick path toward higher precision in Retrieval-Augmented Generation (RAG) pipelines. However, new research from Redis suggests that this practice may be fundamentally undermining the very retrieval capabilities it seeks to enhance.
The study, “Training for Compositional Sensitivity Reduces Dense Retrieval Generalization,” highlights a significant architectural conflict in modern AI. By forcing models to distinguish between nuances—such as reversing the subject and object in a sentence—teams are inadvertently cannibalizing the model’s ability to maintain broad, domain-agnostic semantic recall. The performance dip is non-trivial; researchers observed an 8 to 9 percent degradation in smaller architectures and a startling 40 percent collapse in performance across commonly deployed mid-sized embedding models.
The Geometric Conflict of Vector Space
At the core of the issue is the inherent limitation of embedding-based retrieval. These models function by condensing a complex string of language into a singular coordinate within a high-dimensional vector space. They prioritize topical density, effectively grouping similar subject matter together.
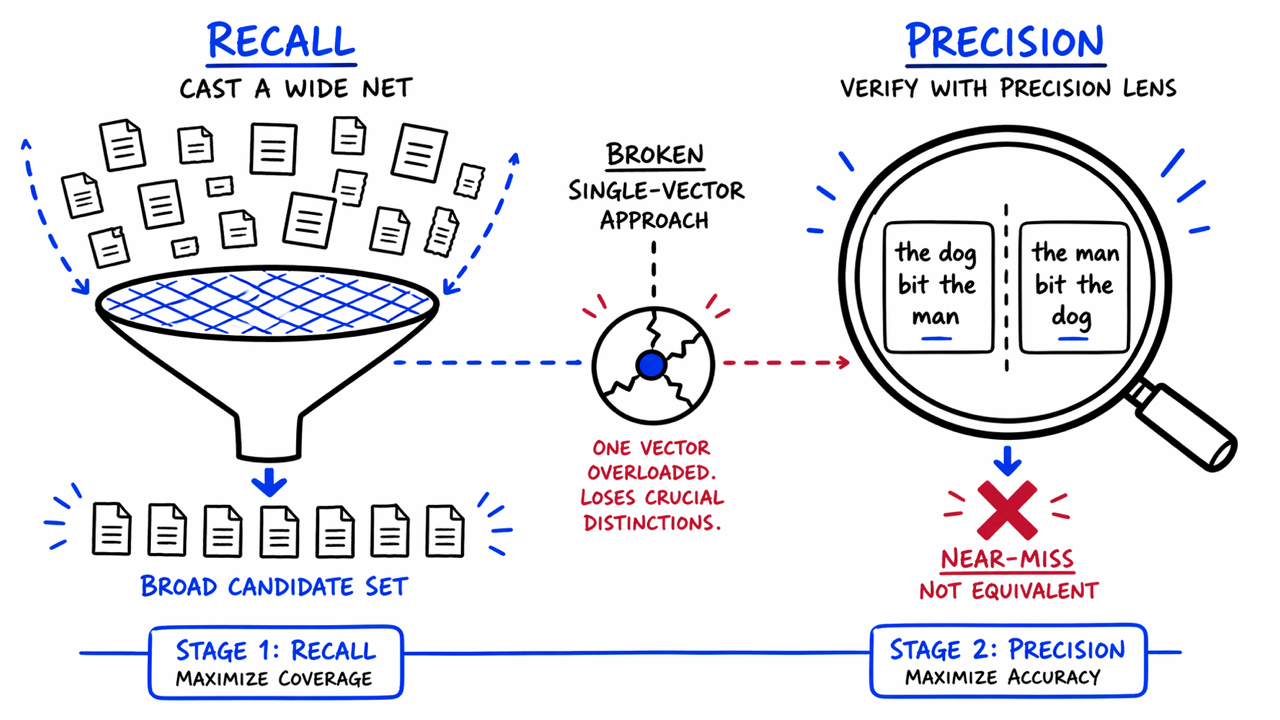
The fundamental failure occurs when engineers attempt to infuse compositional sensitivity—the ability to recognize structural meaning like negations or subject-object swaps—into this same vector. When a model is tuned to differentiate between the dog bit the man and the man bit the dog, it must repurpose the representational space previously allocated for general semantic matching. Because these two objectives compete for the same limited coordinates, solving for structural precision leads to regressing on global retrieval performance. Consequently, the model begins to misfire on unrelated topics it previously handled with ease.
The Fallacy of Standard Architectural Fixes
The industry has largely relied on layered solutions to combat these precision gaps, but the Redis study concludes that these patches are largely ineffective against structural failure modes.
Hybrid Search: By pairing dense retrieval with keyword search, teams hope to catch what embeddings miss. However, when the issue is structural rather than lexical—such as confusing word order—keyword-matching fails to distinguish between two sentences containing the identical vocabulary.
Late-Interaction/MaxSim Scoring: Techniques like ColBERT use token-level comparisons. While this improves relevance metrics in sandboxed environments, it remains blind to structural near-misses, often assigning high similarity scores to statements that have inverted, contradictory meanings.
* Cross-Encoders: While highly accurate, the computational overhead required to perform exhaustive word-by-word comparisons on every query renders them impractical for high-volume enterprise production environments.
Moving Toward a Two-Tier Architecture
The research advocates for a shift in paradigm: stop forcing a single vector to behave as both a broad search engine and a structural validator. Instead, Redis proposes a decoupled, two-stage retrieval pipeline.
Stage One (Recall): Retain the standard dense retrieval approach. The priority here is speed and broad coverage. This stage acts as a wide net, capturing a candidate set of documents based on general semantic relevance.
Stage Two (Precision/Verification): Implement a lightweight, task-specific Transformer model designed solely for verification. This model analyzes the query and the retrieved documents at the token level, specifically looking for role reversals, negations, and modifiers that the initial vector search might have overlooked.
Implications for Agentic AI
For organizations deploying agentic AI, these findings are critical. In a traditional RAG pipeline, a retrieval error might yield a less-than-ideal answer. In an agentic workflow, where a retrieval failure provides the context for a multi-step reasoning chain, that same error can trigger a downstream, automated cascade of incorrect actions.
The takeaway for enterprise architects is clear: do not assume a single-stage, fine-tuned RAG pipeline is inherently production-ready for precision-critical domains like law or finance. Instead, treat retrieval as a multi-stage challenge. Scaling the size of an embedding model is not a panacea for architectural flaws; instead, companies must accept the latency trade-off of a dedicated verification step to ensure the integrity of the data informing their AI decisions.