
Breaking the Turn-Based Paradigm: Thinking Machines Lab and the Future of Real-Time AI
The current landscape of generative AI is defined by a rhythmic, yet awkward, cadence: the prompt-think-output loop. For most users, interacting with models like GPT-4 or Gemini involves a distinct pause—a digital breath taken by the hardware before it can synthesize a coherent response to a static input. Mira Murati’s new venture, Thinking Machines Lab Inc., is aggressively moving to dismantle this turn-based constraint. By introducing its new class of interaction models, the startup aims to replace the high-latency status quo with a fluid, full-duplex communication standard.
The Architecture of Simultaneity
The fundamental problem with large language models today is their underlying reliance on linear, sequence-heavy processing. They wait for an input string to be completed before initiating computation. Thinking Machines has abandoned this inefficient approach in favor of a multistream micro-turn architecture.
By partitioning data processing into 200-millisecond slices, the model can listen, observe, and respond concurrently. This is a significant shift in mechanical logic. Rather than treating an audio-visual input as a static document to be analyzed, the system treats it as a continuous stream of temporal data. This effectively allows the model to perform backchanneling—the ability to acknowledge or react to a user while they are still mid-sentence—mimicking the natural cognitive rhythm of human conversation.
Dual-Model Dynamics: Decoupling Reasoning from Response
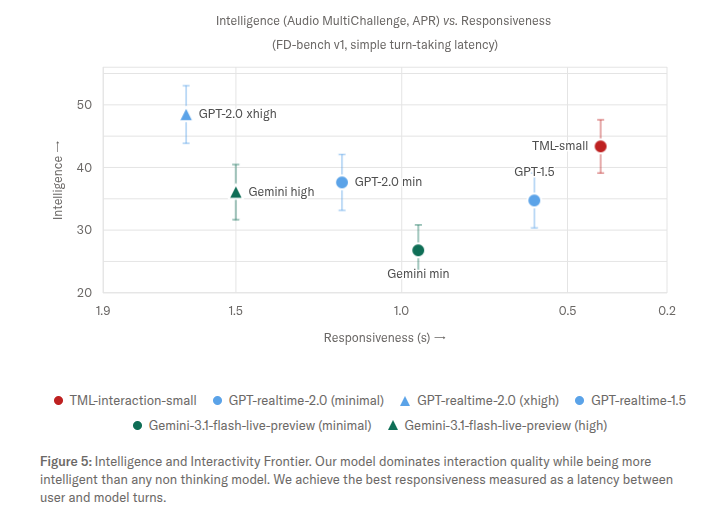
A core architectural innovation from Thinking Machines is the bifurcation of labor between two specialized systems. The “TML-Interaction-Small” model is a 276-billion parameter Mixture-of-Experts (MoE) engine optimized strictly for presence, dialogue management, and rapid reaction.
Simultaneously, an asynchronous “Background Model” handles the heavy lifting—complex reasoning, database lookups, and specialized tool execution. This decoupling is crucial: it prevents high-latency logical tasks from stalling the conversational flow. When the background model completes an intensive task, it feeds the results into the real-time stream. This design suggests a future where AI systems can perform deep research and analysis in total silence, surfacing findings only when they reach a state of readiness, similar to a human consultant who continues to think while a client finishes their sentence.
The Shift Toward Raw Signal Processing
One of the most consequential technical choices outlined by the team is the move toward encoder-free early fusion. By bypassing the heavy, computationally expensive external encoders traditionally used to interpret audio and video, the startup allows raw data to move directly into the transformer architecture via a lightweight embedding layer.
This approach minimizes the translation lag that plagues current multimodal systems. By eliminating the middleman, the model achieves a turn-taking latency of under 0.4 seconds—outperforming industry leaders like Gemini-3.1-flash-live. While sub-second response times may seem like a marginal gain, these milliseconds are the difference between a robotic chatbot and a tool that can function as a high-fidelity colleague.
Industrial and Enterprise Implications
The transition from turn-based to real-time interaction has profound implications for high-stakes industries. While consumer chatbots see incremental improvements from reduced latency, sectors like medicine, precision manufacturing, and real-time security require proactive awareness.
Current AI systems are largely blind to the nuances of evolving contexts. A model that understands time internally and reacts to visual stimuli in real-time could monitor a manufacturing floor for safety violations, instantly issuing a warning or shutting down equipment. Unlike current solutions, which rely on periodic checks, these systems will treat the physical world as a persistent, evolving discourse.
By solving the synchronization gap, Thinking Machines is moving past the AI as a tool phase and into the AI as an agent era. If these benchmarks hold during the upcoming broader rollout, the industry will likely face immense pressure to pivot away from batch-processing architectures, forcing a race toward the low-latency systems required for true autonomous collaboration.